


引言
2024年LLM竞赛正式拉开,被称为OpenAI“最强竞争对手”的大模型公司Anthropic带着Claude 3系列闪亮登场。而它的对手们,一个正和马斯克“扯头花”;另一个因为Gemini政治过分正确而焦头烂额。
一时间,“全面碾压GPT-4”“全球最强模型易主”等字眼铺满屏幕,似乎一年前由OpenAI开辟的盛世终于转交给了Anthropic。
别忘了,GPT-4已经是一年前的产物,GPT-5还在路上;谷歌也不是Anthropic的“对手”,是其背后第二大“金主爸爸”。有消息称,去年12月,谷歌对Anthropic的投资扩大到了20亿美元。
而在这场“你追我赶”的游戏中,还有微软“小儿子”Mistral AI已经发布的Mistral Large,以及被Meta列为2024年重点任务的Llama 3等等。只不过,无论是Mistral AI还是Meta目前都是被GPT-4压着打,只有“脱胎”于OpenAI的Anthropic拿出了可以与之一战的“杀器”。
这也表明了,暂时的排名只是先来后到,今年的LLMs将全面开花,。因此,铺天盖地的“Open AI被追平比分”仅仅是Anthropic新品发布的一个噱头,重点应该放在人工智能公司选择的商业化路径上——当Inflection、Character.AI,甚至OpenAI等公司进一步探向to C消费者用例时,Anthropic却一头扎向了to B。这条思路在其刚刚发布的Claude 3系列的突出性能、定价策略上均有所体现。
一、“田忌赛马”式定价,瞄准to B领域
Claude 3系列包含三个模型——Opus、Sonnet、Haiku,性能从高到低。
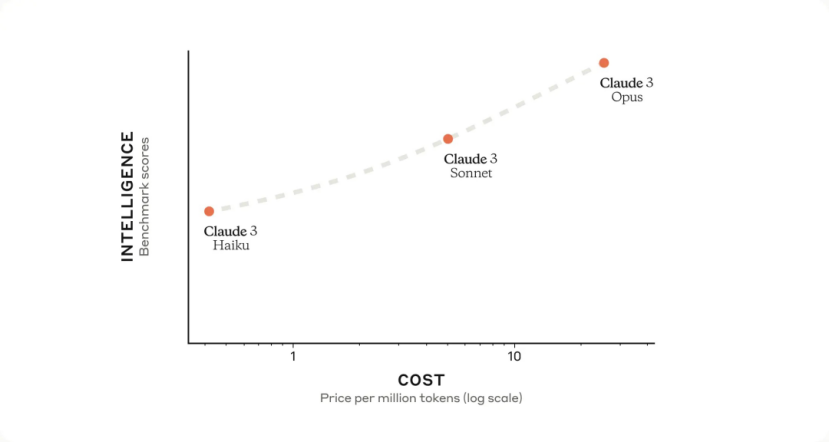
根据Anthropic公布的技术报告,Opus在知识测试MMLU、推理测试 GPQA、基础数学测试 GSM8K 等一系列基准测试中,均优于GPT-4。Sonnet的性能与GPT-4不相上下;Haiku则略逊于GPT-4。不过,这项测试中没有包含刚刚更新的GPT-4 Turbo和Gemini 1.5 Pro。
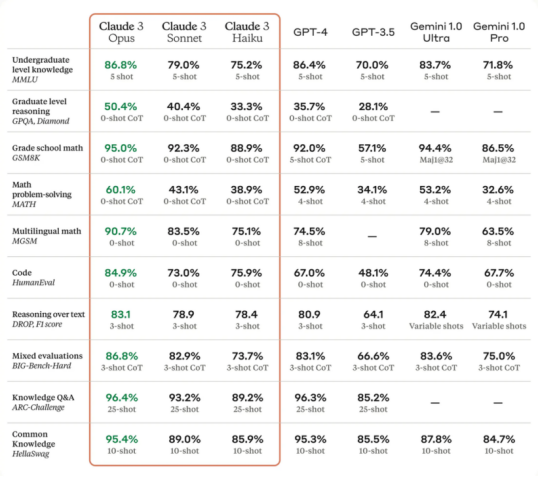
值得注意的是,MMLU(本科常识)/ GSM8K (小学数学)/ HumanEval (计算机代码)等指标上已严重饱和,几乎所有的模型都表现相同。真正有区分度的为MATH(数学问题解答能力)和GPQA(领域专家能力),后者可以体现模型在企业服务方面的能力。
据悉,Claude3 选择了金融、法律、医学和哲学作为专家领域。其中,Opus的GPQA准确率达到了60%,这意味着其能力接近于同一领域且能够上网的人类博士准确率(65%—75%)。Sonnet达40.4%;Haiku达33.3%。而GPT-4仅为35.7%。
对此,英伟达资深AI科学家JimFan指出:我建议所有LLM的模型卡都应该效仿这种做法,这样不同的下游应用就能知道可以期待什么。
同时,考虑到企业客户需要处理很多PDF、PPT、流程图,Claude3 系列在视觉能力、准确性、长文本输入和安全方面,均有所进步。
例如,在准确性方面,Anthropic 使用了大量复杂的事实问题来针对当前模型中已知的弱点,将答案分为正确答案、错误答案(幻觉)、承认“不知道”。相应地,Claude3 可以表示自己不知道答案,而不是提供不正确的信息。除了更准确的回复,Claude 3甚至还能“引用”,指向参考材料中的精确句子来验证他们的答案。
在定价策略上,以GPT-4 Turbo的40美元/1M tokens;GPT-3.5 Turbo的2美元/1M tokens为对比。
最强能力Opus——90美元/1M tokens,适合最尖端的企业和机构。其接近人类的理解能力,适用于需要高度智能和复杂任务处理的场景,如企业自动化、市场分析和制定策略、复杂的数据分析和金融预测、生物医学研究和开发等。
最高性价比Sonnet——18美元/1M tokens,适合大多数企业客户规模化使用,消费者客户也可以负担。其纯文本任务表现与Opus相当,更适用于数据处理、代码生成、个性化营销,图文解析等中等复杂度的工作。
最快速度Haiku——1.5美元/1M tokens,适合消费者客户使用。其具备近乎即时的响应能力,在大多数纯文本任务上表现仍然相当出色,且包含多模态能力(比如视觉),适用于与用户实时互动、内容管理、物流库存管理、文本翻译等工作任务。
综合来看,Claude 3的高端线Opus比OpenAI(GPT-4 Turbo)更贵,低端线Haiku比OpenAI(GPT-3.5 Turbo)更便宜。
如此一来,成败似乎集中在了中端线Sonnet上。如果“更少的幻觉”“更专业的领域行家”“更高的性价比” 更吸引企业客户。那么,GPT-4 Turbo的地位将会变得不尴不尬,直到局势被GPT-5打破。
目前,用户可以免费体验中等性能的Sonnet,最强版Opus仅供Claude Pro付费用户使用(20美金/月),性能稍弱的Haiku即将推出。
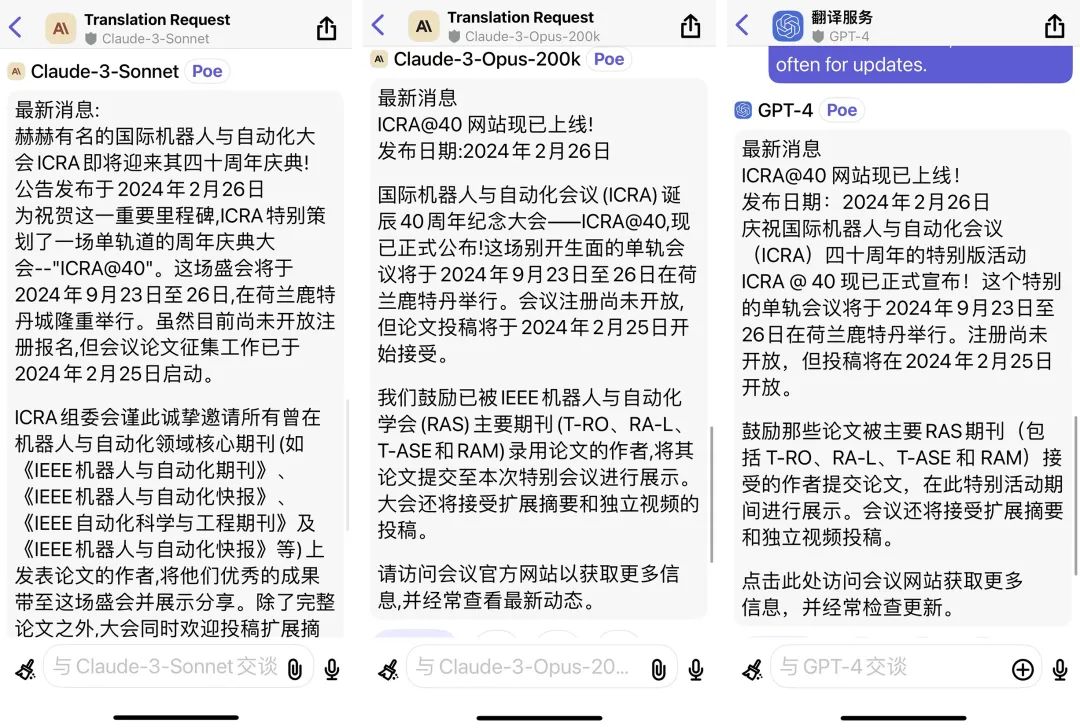
PS:适道在Poe上使用同样的提示语,让Opus、Sonnet、GPT-4 Turbo随机做了一段简单的新闻翻译。结果,Sonnet的表现居然最好,甚至翻译出了缩写!Opus水平巨中,而GPT-4直接忽略了主语。。。
总之,这一套组合拳下来,正如Anthropic联合创始人Amodei兄妹所言:“Anthropic更像是一家企业公司,而不是一家消费者公司。”
目前,Claude的客户包括科技公司Gitlab、Notion、Quora和Salesforce(Anthropic的投资者);金融巨头桥水公司(Bridgewater)和企业集团SAP,以及商业研究门户网站LexisNexis、电信公司SK Telecom和丹娜法伯癌症研究所(Dana-Farber Cancer Institute)。
根据Anthropic高管Eric Pelz的一份声明:在Claude 3的早期测试用户中,生产力软件制造商Asana发现初始响应时间缩短了42%;软件公司Airtable表示,公司已将Claude 3 Sonnet集成到自己的人工智能工具中,以帮助加快内容创建和数据汇总。
可以预见的是,在Claude 3发布之后,Anthropic的to B商业化之路将更加明晰,并与OpenAI等头部大模型公司走上不同的道路,尽管最后可能殊途同归。
二、十字路口的大模型公司
“赚的多,花的多”是头部大模型公司的真实写照。事实上,Anthropic的to B之路既是自愿选择,也是形势所迫。
截至2023年 12 月,OpenAI的ARR 已超16 亿美元,2022年的ARR则为3000万美元,增速高到惊人。
虽然尚无数据显示Anthropic的2023年ARR ,但在2023年10月,Anthropic和投资人洽谈时表示到2023年年底,将实现 2 亿美元 ARR,每月近 1700 万美元的营收。另外,根据 Anthropic 最新预测,到2024 年底,其 ARR 将至少达到 8.5 亿美元。
确实得益于快速的收入增长,2023年Anthropic 筹集了数十亿美元,估值超过 150 亿美元。
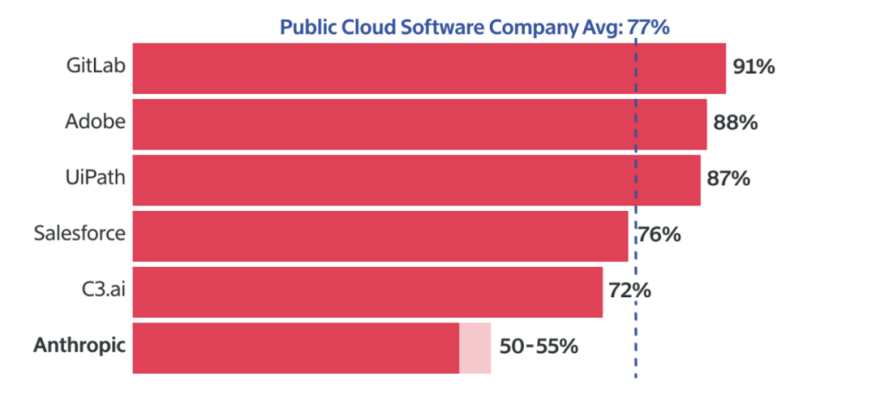
但根据 Information 报道,有两位知情人士透露,在支付客户支持和AI 服务器成本后,2023年12月Anthropic的毛利率在50%—55%,根据Meritech Capital的数据,这远低于云软件公司77%的平均毛利率。
还有一位重要股东预测,Anthropic长期毛利率将在 60%左右,且该毛利率未反映训练 AI 模型的服务器成本,因为这些成本是被 Anthropic 纳入其研发费用中。
而根据 Sam Altman的说法,每个模型成本可高达1亿美元。不过,Altman自己也笑不出来,因为OpenAI的毛利率可能更低。毕竟 ChatGPT还有免费版,白白花掉一批服务器成本。
上述事实均表明,即便你强如OpenAI,Anthropic,但AI初创公司普遍的利润率可能比现在的SaaS公司还低。
不过,现在问题还没显现,毕竟大模型在风口,投资人更关注其惊人的增速。这些AI初创公司也会以其乐观的收入预测为依据,按照未来一年收入的 50—100 倍的估值进行融资。
当然,只要AI创业能保持这种增长势头,投资人是可以忽略亏损。直到,你的收入增长掉进30%—40%。一位VC合伙人表示:到那时,如果一家公司的经营现金流为负,并在短期内没有将至少10% 的收入转化为现金流,就很难吸引新的投资人入局。
根据 Meritech Capital数据,上市软件公司的中位数是未来收入的 6 倍。也就是说,随着时间的推移,对于初创公司来说,维持这样的收入倍数将越来越困难。
具体到Anthropic和OpenAI这对“大冤种”身上,两家公司的增长和利润率部分依赖于主要云服务提供商。
例如,谷歌和亚马逊向 Anthropic 投了数十亿美元,并将 Anthropic 的软件出售给其云客户。目前尚不清楚这些云厂商在销售中获得的提成比例,但如果改成是Anthropic直接向客户卖模型,利润率可能会更高。
而微软虽然用更低的利润租给OpenAI云服务器,但OpenAI 必须将直卖给客户的部分收入返给微软。而且,当微软将OpenAI 软件卖给自己的云客户时,也会抽掉大部分收入。
因此,对于上述“冤种”AI创业公司来说,想要拿到高毛利。一方面,通过更新技术,降低运行成本,就像OpenAI已经实现的;另一方面,像Anthropic“田忌赛马”战略一样,找准切口,聚焦企业客户,尽可能创收,并保持高增速。
据 Forbes报道,Anthropic最近以184亿美元的估值融资7.5亿美元,该公司计划在未来几个月内增加代码解释、搜索功能和源代码引用等功能。其创始人Amodei兄妹说:“我们将继续扩大模型规模,让它们变得更加智能,同时也继续努力让更小、更便宜的模型变得更智能、更高效。一整年都会有不同程度地更新。”
三、大模型公司会否下场做选手?
为了更深入理解Anthropic的商业化路线,适道节选了一期创始人Dario Amodei访谈中的“商业化”部分,原文如下。
Dwarkesh Patel :你认为目前的 AI 产品是否有足够时间在市场上获得长期稳定收入?还是随时可能被更先进的模型取代?或者到时候整个行业格局会变得完全不同?
Dario Amodei :这取决于对“大规模”的定义。目前已经有几家公司的年收入1 亿—10 亿美元,但能否达到每年数百亿,甚至万亿级别,则难以预测。因为这还取决于很多不确定的因素。现在有些公司正在“大规模”应用创新型 AI,但这不能代表刚开始用就一步到位,达到最佳效果。而且,即使有收入也并不完全等于创造了经济价值,整个产业链的协同发展是一个长期过程。
Dwarkesh Patel :从Anthropic角度来看,如果LLM的进步如此迅速,那么理论上公司的估值应该增长得很快?
Dario Amodei :即使我们注重模型安全性研究而非直接商业化,在实践中也能明显感受到技术水平在以几何级数上升。对那些将商业化视为首要目标的公司来说,进步肯定比我们更快。(xswl在内涵OpenAI )。
虽然我们承认LLM进步神速,但对比整个经济体系的深度应用过程,技术积累依然处于较低的起点阶段。决定未来走向是这二者间的竞速——技术本身进步速度、被有效整合和应用,并进入实体经济体系的速度。这二者都很可能高速发展,但结合顺序和微小差异都可能导致相当不同的结果。
Dwarkesh Patel :科技巨头可能会在未来 2-3 年投入高达 100 亿美元进行模型训练,这会对 Anthropic 带来什么样的影响?
Dario Amodei :情况1——如果因为成本问题无法保持前沿地位,那么我们将不会继续坚持开发最先进的模型。相反,我们会研究如何从前几代的模型中获取价值。
情况2——接受被制衡。我认为这些情况的正面影响可能比它们看起来的要更大。
情况3——当模型训练到达这种量级后,可能开始会出现新的风险,比如AI 滥用。
总结一下,虽然Dario坚信LLM的能力会得到快速且显著的提升,但可能受制于社会因素、创新采纳效率,最终减缓其被“大规模”应用的速度,无法发挥LLM的真正潜力。
据此,Anthropic的to B之路看起来也更加稳妥。一方面,利用自己的“安全性”长处,切入金融、法律、医学等领域;另一方面,寻找偏重“技术应用”,可以长期合作的企业客户,尽可能消除C端消费者采用的不确定性。
说到这里,我们可以大胆预测一下,如果真如Dario预测的“社会采纳速度低于模型发展速度”,那么,未来会否出现一批大模型公司亲自下场做应用?尤其在国内。
原创文章,作者:适 道,如若转载,请注明出处:https://www.shidaox.com/observation/1836.html